- 논문 제목: Very Deep Convolutional Networks for Large-Scale Image Recognition (대규모 이미지 인식을 위한 매우 깊은 합성곱 신경망)
- 저자: Karen Simonyan & Andrew Zisserman
- 게재된 학술지/학회: ICLR 2015 (International Conference on Learning Representations)
- 발표 연도: 2015 (초고는 2014년 arXiv에 공개)
- 논문 링크: https://arxiv.org/pdf/1409.1556
1. Summary
- 2012년, ILSVRC (ImageNet Large Scale Visual Recognition Challenge) 에서 AlexNet이 대성공을 이룬 이후 수많은 딥러닝 기반 시도들이 있었다.
- 그중 VGG Net은 2014년 준 우승작으로, 2014년엔 GoogLeNet이 우승을 했지만 지금까지도 VGG Net이 기억받는것은 단순한 구조로 뛰어난 성능을 내서 그런것 같다. 사실 논문에도 나오는 내용이지만, GoogLeNet 또한 VGG Net과 같은 아이디어로 작은 Convolution filter와 깊은 Depth로 뛰어난 성능을 이끌어냈다.
- VGG Net은 작은 컨볼루션과 망 깊이를 깊게 함으로 직관적으로만 가지고 있던 깊이가 깊어지면 성능이 올라간다는 생각을 보여주었다는 것에 큰 의미를 가진다. 3x3의 상하좌우를 이해하는 최소의 크기만의 컨볼루션을 쓴것이 오히려 깊이의 힘을 보여주지 않았을까.
- 그 다음년도 2015 우승작은 ResNet. 이 논문이 깊이의 힘을 보여줬다면 ResNet은 깊이를 깊게 했을때 생기는 기울기 소실을 잔차 연결로 해결하는것을 보여준다.
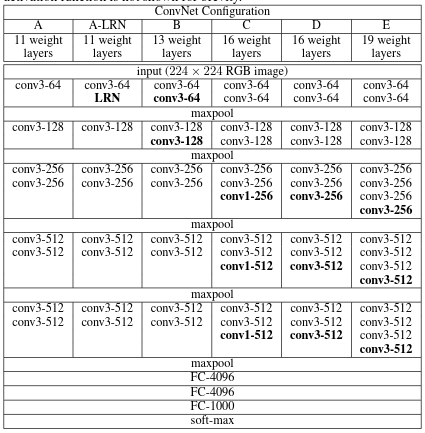
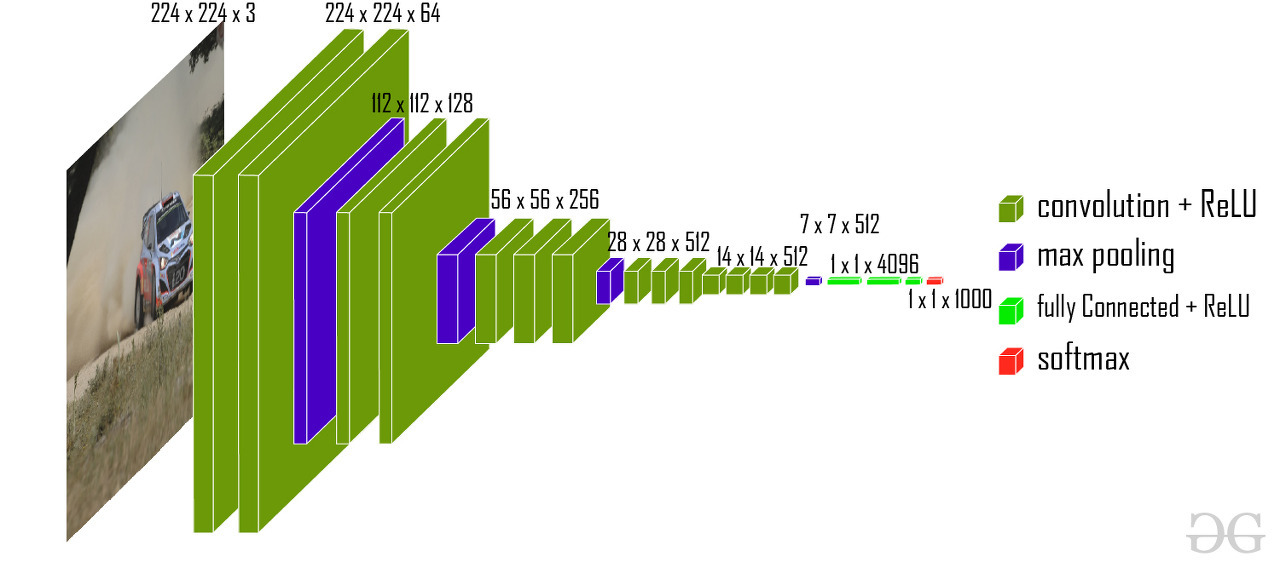
2. ConvNet Configurations
- 입력: 224 x 224 RGB(x3) 이미지
- 컨볼루션: 모든곳에서 동일하게 3x3 사이즈의 커널이지만, max pooling 한 다음 컨볼루션은 채널 크기가 512 미만일때 채널 크기를 2배로 늘림. padding을 1씩 넣고, stride가 1이라서 컨볼루션 연산시에는 이미지 사이즈가 유지됨. 모든 컨볼루션 뒤에는 ReLU 함수를 추가한다.
예외적으로 VGG16에서는 conv1이 나와서 선형 연산이니깐 의미 없는거 아닌가? 하고 생각할 수도 있지만, 선형 연산이라도 뒤에 있는 활성화 함수에 의해 복잡도가 높아져 설명력이 올라간다.
- max pooling: 2x2 사이즈, stride는 2이므로 이미지는 2배 작아진다.
- FC layers: Depth와 관계없이 총 3층으로 되어있고, 첫번째와 두번째 층은 4096채널, 세번째 층은 1000채널로 되어있고 활성화함수는 ReLU
표로 구성요소를 나타면 다음과 같다.
이렇게 3x3으로만 구성하고 깊은 망을 만듦의 장점은 무엇일까?
1. 동일한 Receptive Field, 낮은 파라미터
위 사진에서 보이는것 처럼 3x3을 두겹 쌓는것으로 5x5의 Receptive Field를 가지고 있는것을 볼 수 있다. 하지만 파라미터 수는 어떨까? conv5 하나와 conv3 두개를 생각해보면, conv5는 , conv3 두개는 이다. 만일 와 세개를 비교해보면 , 로, conv7쪽이 파라미터가 81%정도 더 많은걸 볼 수 있다.
2. 많은 활성화 함수 → 많은 비선형성
위 표에서는 가시성을 목적으로 ReLU를 적지 않았지만 모든 Conv뒤에 들어가있다.
3. Training / evaluation
training:
- 작은 모델을 먼저 학습시키고, 그 모델의 가중치를 큰 모델에 가져와서 큰 모델을 더 학습시키는 방법을 사용했다. 이게 일반적으로 쓰이는 방법인진 모르겠지만 흥미로웠다.
- 학습에 사용되는 이미지는 스케일은 처음엔 작은면이 255가 되게 한 후 224x224를 랜덤으로 잘랐고, 두번째는 작은면을 에서 랜덤 샘플링해서 랜덤으로 잘랐다 (스케일 지터링) 랜덤 좌우반전과 RGB colour shift도 행했다.
evaluation:
- top-1 error: 모델이 예측한 top-1안에 정답이 들어있는지에 대한 오류
- top-5 error: 모델이 예측한 top-5안에 정답이 들어있는지에 대한 오류
- FC를 Conv로 바꿔서 이미지 전부에 모델을 한번씩 적용하는 방법(Fully-Convolutional Net)과 멀티크롭, 두가지 방법으로 evaluation을 행한 후 비교했음.
4. Experiments
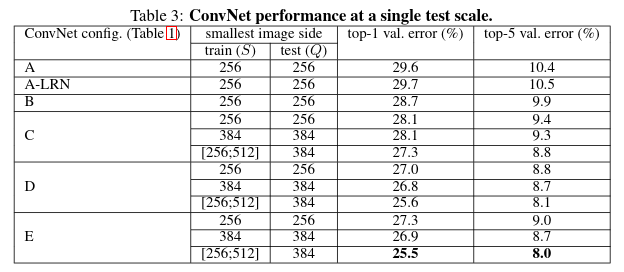
Single scale evaluation:
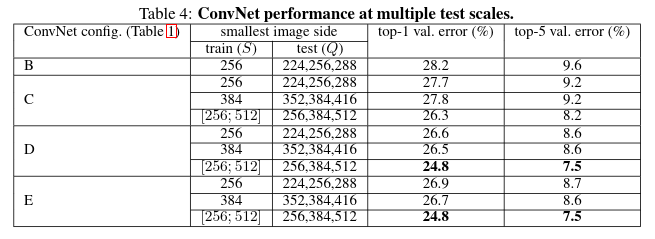
MULTI-SCALE EVALUATION:
MULTI-CROP EVALUATION: