- 논문 제목: Training language models to follow instructions with human feedback (인간 피드백을 통한 지시 이행 언어 모델 훈련)
- 저자: Long Ouyang, Jeff Wu, Xu Jiang 외 OpenAI 연구팀
- 게재 정보: arXiv (Preprint), NeurIPS 2022 (이후 학회 발표됨)
- 발표 연도: 2022년
- 논문 링크: https://arxiv.org/pdf/2203.02155
Summary
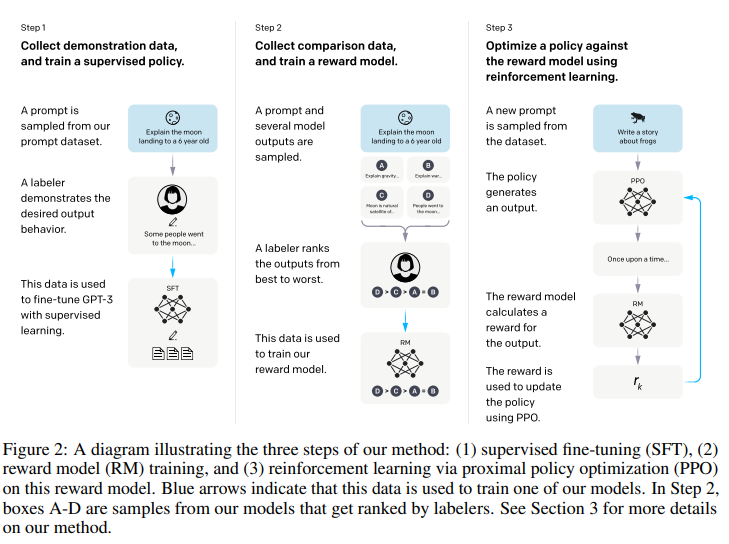
언어모델을 단순히 크게 만드는것으로는, 언어모델을 “정렬”하게 만드는 것을 달성하지 못함. 즉, 언어모델은 여전히 인터넷에서의 다음 단어 예측을 할 뿐이고, 사람에게 도움이 되는 분포를 따르진 않음. 이 논문은 RLHF를 이용해 언어모델을 정렬시켜 사람에게 도움이 되도록 학습한 모델이 크기가 100배 큰 모델보다 더 나은 평가를 받는걸 보이면서, 정렬의 중요성을 알린 패러다임 변환 논문이라고 볼 수 있다.
Methods
Step 1: SFT (Supervised Fine-Tuning)
데이터 라벨러가 프롬프트에 라벨링을 해 (프롬프트, 사람이 작성한 모범 답안) 쌍을 만들어, 파인튜닝함. 이 데이터의 질이 매우 중요함.
Step 2: RM (Reward Modeling)
리워드 모델인 를 학습시키기 위한 로스함수. 리워드모델은 기존 LLM이랑 똑같지만, 맨 마지막에 숫자를 내놓도록 한 언어모델입니다. 논문에서는 175B에서는 학습이 불안정해서 6B를 썻다고 합니다.
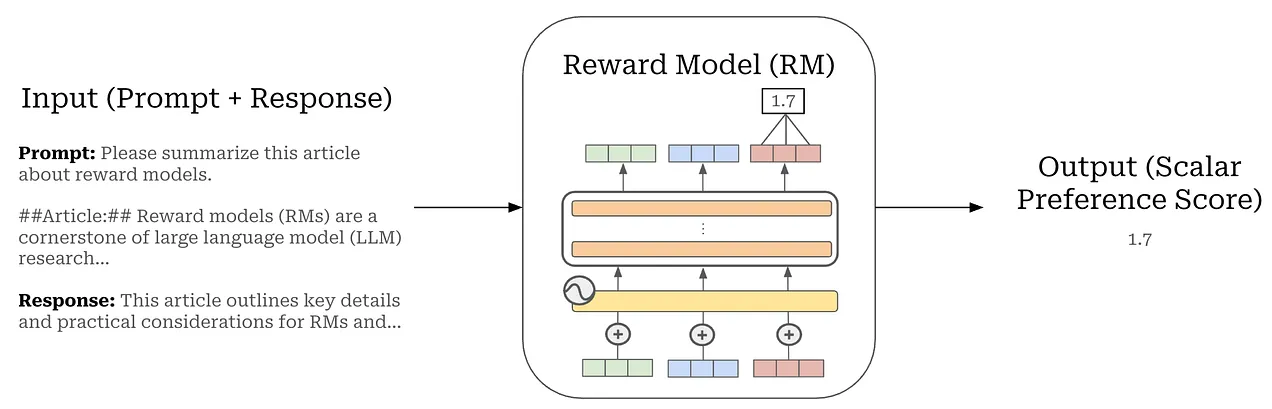
Bradley-Terry 선호도 모델등 RM에 대한 더 깊은 정보: https://cameronrwolfe.substack.com/p/reward-models
Step 3: Reinforcement Learning via PPO
이는 다르게 쓰면 이렇게 쓰일 수 있다.
(1) 보상 획득
방금 만들었던 RM모델의 보상으로 학습하는 과정이다.
(2) KL 패널티
수식적으로 보면 두번째 항이 와 같은걸 알 수 있는데, 이는 SFT에서 얻은 모델의 분포와 RL에서 얻은 분포가 너무 달라지지 않게, 즉 보상 모델의 허점을 파고들어 이상한 문장을 만들거나(Reward Hacking), 말이 안 되는 소리를 하는 것을 막는다.
(3) 사전 학습 유지
모델이 보상에 집중하다보면 Pretraining에서 얻은 일반적 지식인 역사, 과학, 번역 능력등을 잃어버리는 “정렬 세금”효과가 있는데, 3번째 항을 잘 보면 수식적으로 사전학습할때 쓰던 Cross entropy에 를 곱한 것과 같다. 이를 통해 모델은 사전학습에서 얻었던 일반적 지식을 잃어버리지 않을 수 있다.
Results
(추후 추가 예정)
Conclusions
이 논문은 “어떻게 하면 AI를 사람에게 유용하게 만들 것인가?” 라는 질문에 대해, RLHF라는 강력한 대답을 내놓은 연구다. 우리가 누리는 ChatGPT의 은혜가 바로 이 논문에서 설계된 RLHF 학습 방법론 덕분… 패러다임을 변환시키는 아주 중요한 논문이였던 것 같다.