- 논문 제목: Chain-of-Thought Prompting Elicits Reasoning in Large Language Models (사고의 연쇄 프롬프팅은 대규모 언어 모델의 추론 능력을 이끌어낸다)
- 저자: Jason Wei, Denny Zhou 등 Google Research 소속 연구원들
- 게재된 학술지/학회: NeurIPS 2022 (Neural Information Processing Systems)
- 발표 연도: 2022년
1. Summary
GPT-3가 등장하면서 스케일링 법칙이 대세가 됨에 따라, 일단 모델 크기를 키우면 모든것이 해결 될 꺼란 당시의 분위기가 있었다.
하지만 언어모델은 여러 단계의 논리적 사고를 필요로 하는 arithmetic, commonsense, symbolic reasoning 같은 문제들은 여전히 풀기 힘들어 하였다.
기본적으로 CoT 프롬포팅 논문은 Rationale 과정을 생성하게 고비용의 연산을 통해 파인튜닝 하여 성능을 올린 기존 연구와, 프롬포팅을 통한 in-context few-shot learning 을 혼합한 결과물이다.
프롬포팅으로 문제, 풀이과정, 답을 순서대로 제공하여 모델이 추론과정을 포함하여 언어를 생성하게 되었고, 그로 인해 복잡한 문제에서 SOTA를 달성 할 수 있었다.
결국 지금은 일단 모델 크기를 키우면 모든것이 해결 될 꺼란게 아니라, 어떻게 추론을 잘 시킬지 CoT과정을 열심히 강화학습 하게 하고있으니, 이 논문은 별거 아닌것 처럼 보이지만 패러다임 전환 논문인것…
2. Chain-of-Thought Prompting
인간이 일반적으로 수학 문제를 풀때 우리 머릿속에서 돌아가는걸 생각해보자. 우리는 다음과 같이 생각한다.
“Jane이 엄마에게 꽃 2송이를 주고 나면 10송이가 남고… 그 다음 아빠에게 3송이를 주면 7송이가 남게 되므로… 정답은 7이다.”
언어모델에도 다음과 같은 “생각 과정”을 주면 성능이 향상된다는것은 이전 파인튜닝 논문으로 널리 알려져있다.
하지만 이 논문에서는 프롬포팅까지 하지 않더라도, 퓨샷 프롬포팅의 예시에 몇개의 CoT 과정을 포함시키는것 만으로 LLM이 CoT과정을 할 수 있다는걸 보여준다.
연구자들은 “풀이”라는 말 대신 CoT라는 용어를 사용한다. 이는 풀이는 우리가 사후적으로 적는것 같은 어감을 가지지만, CoT는 생각의 흐름이 언어로 나타나는 과정을 더 잘 표현하기 때문.
이런 CoT는 여러 멋진 성질을 가지고있다.
- 모델이 여러 단계의를 가진 문제를 중간 단계들로 분해할 수 있도록 허용한다.
- CoT는 모델의 행동 원리를 들어다 볼 수 있는 해석 가능성을 제공한다.
- 이론적으로 인간이 언어를 통해 해결 가능한 모든 문제에 적용가능하다.
- 프롬포팅에 사고과정을 포함시켜서 LLM을 그대로 쓸 수 있다. 너무 편하다.
3. Arithmetic Reasoning
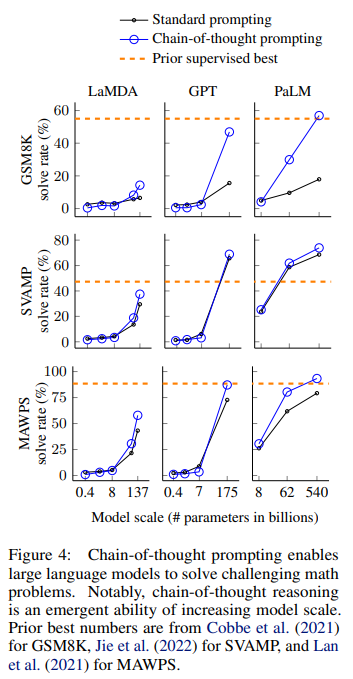
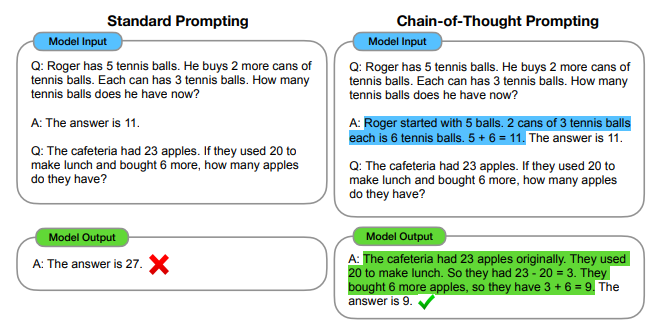
실험은 맨위에 있는 사진처럼 답만 있는걸 Standard prompting, 사고 과정을 적은것을 CoT prompting 으로 하여 테스트 한 결과이다.
- 또한 작은 파라미터에서는 잘 나타나지 않고, 큰 파라미터에서 두드러지게 나타나는걸 보아 연구자들은 추론이 “창발적 속성”이라고 주장한다.
- GSM8K같이 복잡한 문제에서 성능이 확 뛰어오르는 것을 볼 수 있다. MAWPS 에서는 성능 향상 폭이 엄청나게 크진 않다.
- 파인튜닝보다 성능이 잘 나왔다.
Ablation Study
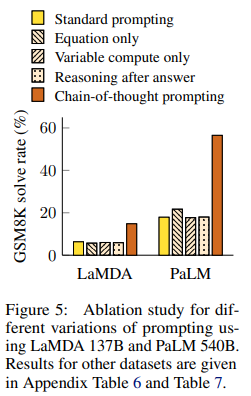
- Equation only: 중간에 수식을 만들어서 그런거 아닐까?
문제 -> 수식 -> 답형식의 프롬포트를 시도 - Variable compute only: 그냥 연산량이 높아서 그런거 아닐까?
문제 -> ....(점 여러개) -> 답형식의 프롬포트 사용 - Chain of thought after answer: 제목이 곧 내용.
전부 CoT 보다 성능이 훨씬 안 좋았다!
Robustness of Chain of Thought
기존 연구에서는 퓨샷 예시의 순서만 바꿔도 GPT-3의 정확도가 찍기수준 (54.3%)에서 SOTA수준 (93.4%) 까지 변동할 수 있다는 연구가 있었다. (Zhao et al., 2021)
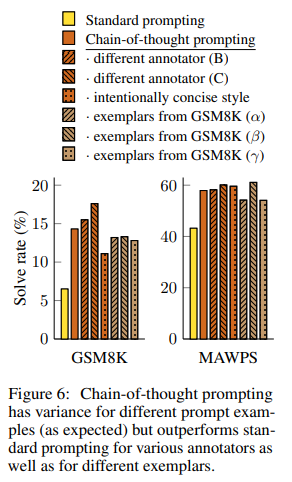
다른 작성자 B,C가 쓴 CoT 과정과, 8개의 예시중 3세트를 샘플링 한 실험도 진행헀다. 모든 경우에서 일반 프롬포팅보다 CoT 프롬포팅이 성능이 좋았다!
4. Commonsense Reasoning
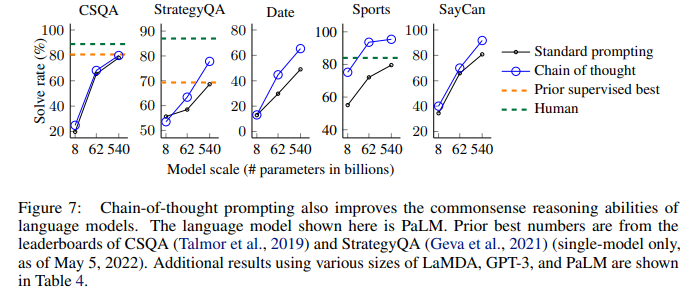
사실 CoT는 수학 기호만 쓰는게 아니라 자연어로 생각의 흐름을 표현하는 것이기 때문에, 광범위한 종류의 상식 추론 문제에도 적용가능하다.
벤치마크는 다음과 같다.
- CSQA: 간단한 상식 퀴즈 (예: “종이를 자를 때 쓰는 것은?“)
- StrategyQA: 여러 단계를 거쳐야 답이 나오는 상식 문제 (예: “헤라클레스가 아스피린을 먹을 수 있었을까?” → 헤라클레스는 신화 속 인물 → 아스피린은 현대의 약 → 따라서 불가능)
- Date Understanding / Sports Understanding: 특정 도메인(날짜, 스포츠)에 대한 지식과 추론 능력을 함께 평가합니다.
- SayCan: “배고픈데 과일 말고 다른 거 줘”라는 말을 들었을 때, 로봇이 1. 에너지바를 찾는다 → 2. 에너지바를 집는다 → 3. 사용자에게 간다 → 4. 에너지바를 내려놓는다 와 같은 행동 계획을 세우는 능력. 이는 추론이 실제 행동으로 이어지는 실용적인 능력을 측정합니다.
수학에서와 동일하게 성능이 향상된걸 볼 수 있다. 이는 CoT가 수학 문제 아니라 일반적인 문제를 잘 풀게할 수 있는 범용적 추론 성능을 늘리는걸 보여준다.
5. Symbolic Reasoning
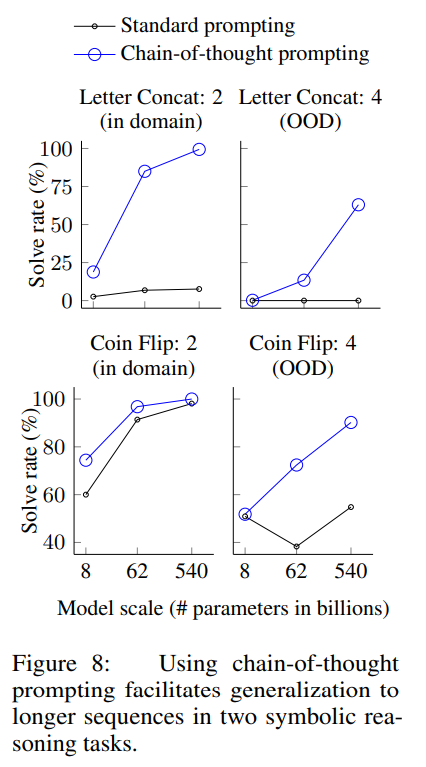
기호 추론은 인간에겐 단순하지만 언어모델에게는 잠재적으로 어려운 과제이다. 이 논문에서는 언어모델이 어려운 기호추론 문제를 해결 할 수 있을 뿐 만 아니라 예시에서 본 것보다 더 긴 입력에도 length generalization를 하는것을 보여준다.
간단한 두개의 toy 과제:
- 마지막 글자 이어붙이기. 이 과제는 이름에 있는 단어들의 마지막 글자들을 이어붙이도록 모델에게 요청합니다 (예: “Amy Brown” → “yn”)…
- 동전 뒤집기. 이 과제는 사람들이 동전을 뒤집거나 뒤집지 않은 후에 동전이 여전히 앞면(heads up)인지 답하도록 요청합니다 (예: “동전이 앞면이다. Phoebe가 동전을 뒤집는다. Osvaldo는 동전을 뒤집지 않는다. 동전은 여전히 앞면인가?” → “아니오”).
OOD는 사람이 3명, 4명 나오는 문제로 바뀐다.
기존 프롬포팅은 모델 크기가 커져도 정답률이 거의 변함이 없지만, CoT프롬포팅을 하면 OOD에서도 우상향하는 정답률을 볼 수 있다.
결론
- CoT를 통해 처음보는 규칙을 성공적으로 학습함
- 더 복잡한 상황에서도 일반화 하여 적용 가능함.
6. Discussion
연구 함의
- 스케일을 크게 해도 오르지 않던 평평한 선을 CoT를 통해 상승하는 곡선으로 만들어냄.
- 새 질문 1: 스케일링 법칙의 한계는?
- 새 질문 2: CoT보다 잘 되는 프롬포팅 방법은 없을까?
한계
- CoT가 인간이랑 비슷하게 사고과정을 하긴 하지만, 이것이 진짜 추론인지는 불분명함.
- CoT 어노테이팅 비용이 싸긴 하지만, 파인튜닝과 결합하려면 파인튜닝을 위한 어노테이션 작업 비용이 굉장할것.
- 추론 경로가 올바를 것이라는 보장이 없다. (이건 지금도 큰 문제인듯, 추론경로 고칠 방법도 없고…)
- 대규모 모델에서만 나타나므로 실제 서비스에서 사용하기에 비쌀것.
7. Conclusions
클래식은 클리셰가 되어 참신함이 사라진다는 말이 있는데, 이 논문도 클리셰가 된 클래식류 일지도 모른다.
또한 차근차근 사고하게 프롬포팅 한다는 내용과, 후속 연구인 “차근차근 생각해” 같은게 너무 널리 알려지기도 하고 그랬지만,
결국 현대 LLM들은 스케일을 우당탕 늘리는것 보단, 어떻게 CoT를 잘 할지 열심히 고민한다는걸 생각해보니 멋진 시작점이 되는 논문이였던 것 같다.