- 논문 제목: Mixtral of Experts
- 저자: Albert Q. Jiang, Alexandre Sablayrolles, Antoine Roux 외 다수 (Mistral AI 소속 연구원들)
- 게재된 학술지/학회: unknown
- 발표 연도: 2024년 1월
- 논문 링크: https://arxiv.org/pdf/2401.04088
Summary
스케일링 법칙에 따라 “LLM은 파라미터 크기가 클수록 성능이 좋아진다”는 것은 확실하였다. GPT-3, Llama 2 70B 등은 큰 파라미터를 통해 성능을 끌어올렸는데, 여기에는 당연히 따라오는 문제가 하나 있었다. 파라미터 수가 커질수록 비용이 기하급수적으로 커지는 문제가 있었던것.
이 논문에서는 Mixtral 8x7B 는 Sparse Mixture of Experts (SMoE) 아키텍쳐를 구현하여 적은양의 총 파라미터는 47B 이지만 실제 추론 시 사용되는 파라미터는 13B로, 효율성을 달성하면서 동시에 SOTA급 성능을 달성하였다.
Architectural details
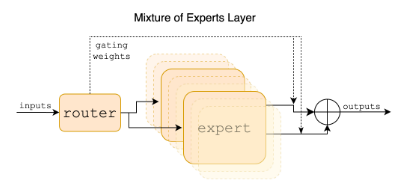
Mixtral 8x7B은 기본적인 트렌스포머 구조에 Mistral 7b와 동일한 수정사항을 가진다. 중요한 부분은 feed-forward blocks이 Mixture-of-Expert layers로 수정된다는 부분이다. 위에 있는 사진은 Mixture-of-Expert layers의 구조를 잘 보여주는데, 앞에 있는 라우터가 8개의 전문가중 2개에게만 게이팅을 해줘서 비용을 최적화하면서 좋은 결과를 내보낼 수 있게된다.
Mixture-of-Expert layers의 출력은 다음과 같다.
는 n차원 출력의 게이팅 네트워크의 출력이다. 는 번째 전문가 네트워크의 출력이다. 논문에서는 다음과 같은 를 이용한다.
행렬을 곱하고, TopK개만 유지하고, 나머지를 0으로 만들고 Softmax를 적용하는 단순한 게이팅 네트워크다. 직관적이다! 는 SwiGLU를 사용한다고 한다.
MoE는 그 구조상 전문가를 여러개의 GPU에 나누어 연산할 수 있는데 이를 Expert Parallelism이라고 한다고 한다. (이 부분은 패스…)
Results
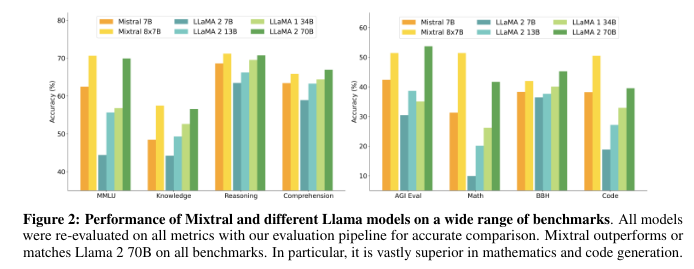
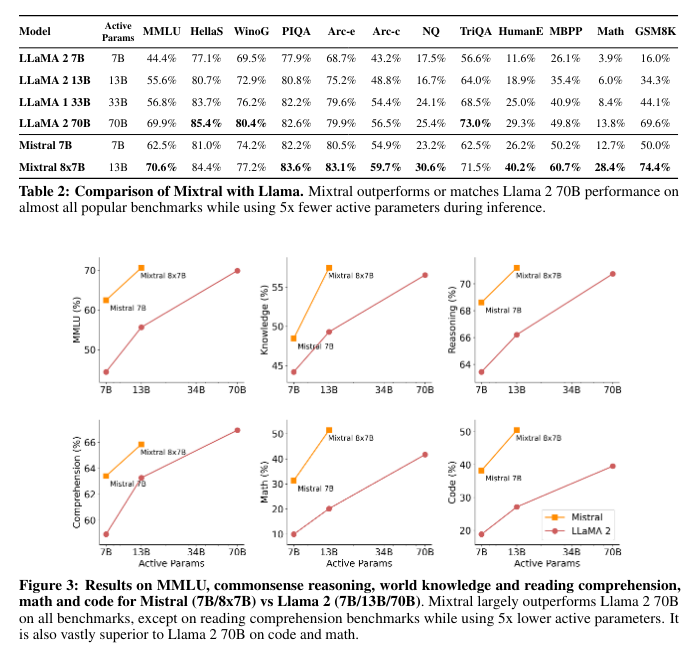
조금의 활성 파라미터만 가지고 70B 모델하고 비비고 있다. 대단하다.

사전학습 시 다국어 데이터의 비율을 크게 늘렸다고 한다.
Routing analysis
여기가 사실 논문보면서 제일 흥미로웠던 부분이다.
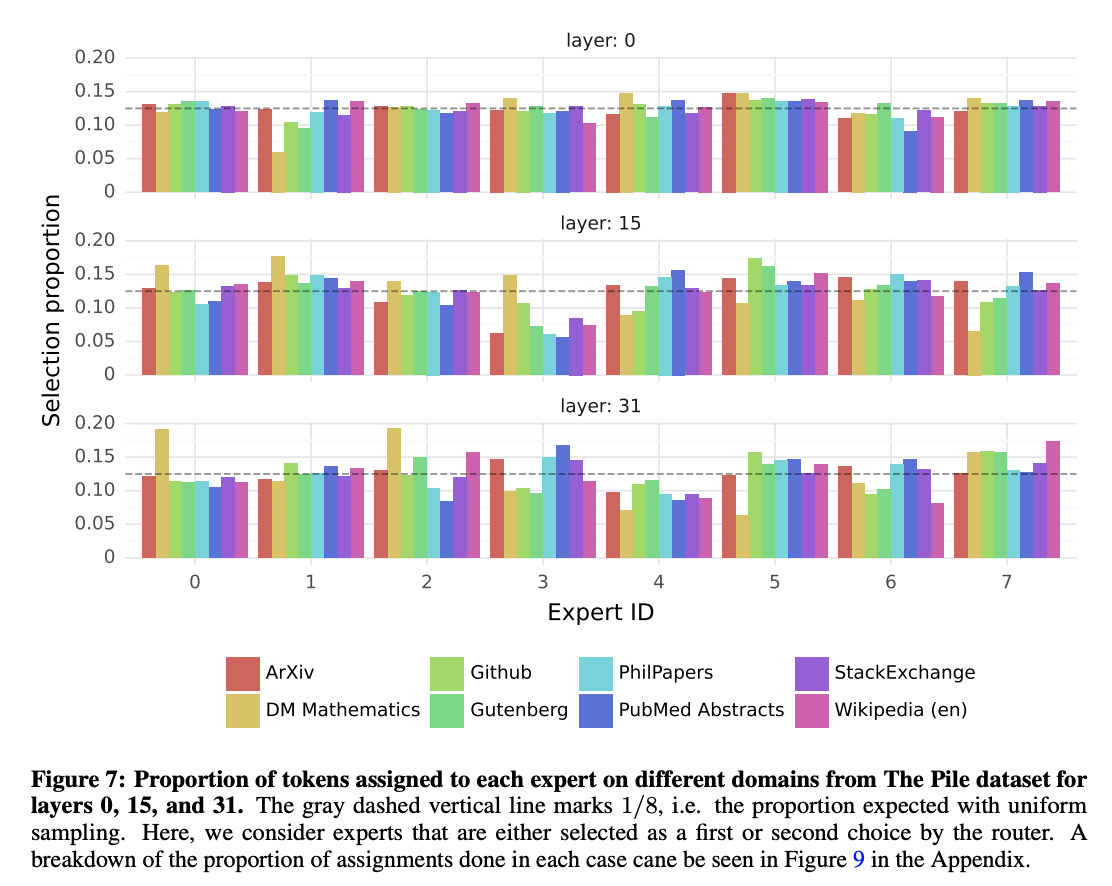
MoE 모델이지만, 실제로 어떤 네트워크가 어떤 분야에 대해서 더 활성화가 되는지의 관계는 찾지 못했다고 한다. 노란색으로 표시된 DM Mathematics 만 살짝 다른 분포를 보였는데, 이는 DM Mathematics가 인공적으로 생성된 데이터셋이고, 자연어를 제한적으로만 다루기 때문이라고 추측한다.

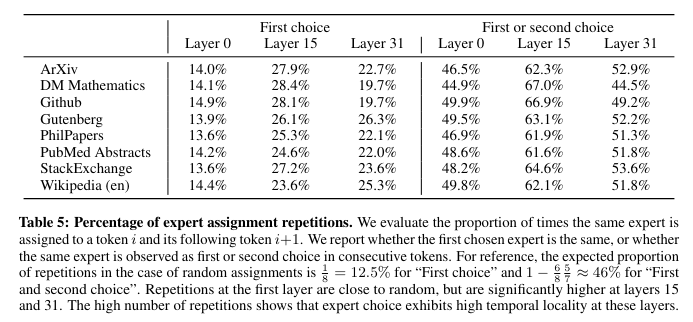
하지만, 완전히 규칙을 찾지 못한것은 아니다. 어떤 토큰을 어떤 전문가가 해결할때, 다음 토큰도 그 전문가가 해결할 가능성이 굉장히 높은것을 토대로 저자들은 구문적 패턴에 따라 라우터가 전문가를 고른다고 주장한다. 예시로 ‘self’, ‘Question’ 같은 단어는 여러 토큰으로 이루어져 있지만 많은 때 같은 전문가로 라우팅 된다는것은 근거로 들 수 있다. 또한 코드에서 인덴트는 특정 전문가가 치는 경우가 많은것을 확인할 수 있다.
Conclusion
이 논문은 사실 있던 방법을 그대로 해서 보여준거긴 하지만, SOTA를 달성함으로써 MoE가 실제로 얼마나 잘 되는지 보여준것이 가장 큰 시사점일것 같다. 회사 입장에서 새로운 아키텍쳐를 학습하면서 돈을 투자하는게 고민 됐을텐데…
여담이지만, 이 모델이 가중치를 공개해서 오픈소스로 풀렸을때 허겁지겁 달려가서 가중치 다운로드 받던 기억이 있다. 아직까지 NAS에 있긴 한데, 오픈소스 모델들이 성능이 너무 좋아져서 이미 쓸모가 없긴 하다…