- 논문 제목: A Simple Framework for Contrastive Learning of Visual Representations (시각적 표현을 위한 대조 학습의 간단한 프레임워크)
- 저자: Ting Chen, Simon Kornblith, Mohammad Norouzi, Geoffrey Hinton
- 게재된 학회: Proceedings of the 37th International Conference on Machine Learning (ICML)
- 발표 연도: 2020
- 논문 링크: https://arxiv.org/pdf/2002.05709
Summary
Visual Representations을 Contrastive Learning으로 배우는 간단한 프레임워크인 SimCLR을 소개한다.
이 논문에서는 실험과 함께 다음 세가지를 보여준다.
- 여러가지 데이터 증강 기법의 조합은 예측 과제를 정의하는데 결정적인 역할을 한다.
- 학습 가능한 비선형 변환을 표현과 로스함수 사이에 넣음으로 학습된 표현의 수준을 끌어올릴 수 있다.
- Contrastive Learning은 supervised learning에 비해 큰 배치와 많은 학습 스텝에서 더 큰 이득을 본다.
기존 방법보다 성능이 7% 가량 향상되어 SOTA를 달성하면서, 기존 방법에서 쓰던 특별한 아키텍쳐나 메모리뱅크등을 필요로 하지 않는 간단한 구조를 가진다는 점에서 의미가 크다.
Method
The Contrastive Learning Framework
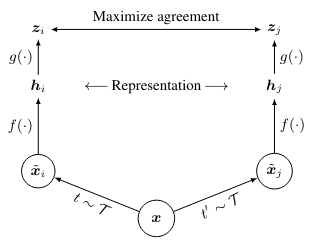
-
하나의 이미지 에서 서로다른 데이터 증강 조합(예: 이미지 자르기 + 색상 왜곡)을 적용하여 한 쌍 이미지 를 만든다.
-
그 다음, 이미지의 표현 벡터를 얻기 위해 인코더 네트워크인 를 적용하여 를 구한다. 논문에서는 ResNet을 사용한다.
-
“projection head” 라고 불리는 작은 뉴럴 네트워크인 를 이용하여 이미지의 표현벡터에서 로스함수에 들어갈 값으로 변환한다. 논문에서는 where is ReLU 를 사용한다.
-
미니배치당 N개의 이미지를 샘플링 하고, 증강을 해서 2N개의 data points를 얻는다. 우리는 negative examples을 따로 샘플링 하지 않고 미니배치에 있는 다른 2(N-1)개를 모두 negative examples처럼 다룬다.
-
(코사인 유사도) 라고 하면, 두 긍정쌍의 로스함수는 다음과 같다.
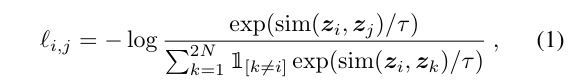
위 식을 잘 보면, 긍정쌍인 의 유사도를 최대화 해야하고, negative examples들인 의 유사도는 낮게 해야 로스함수를 낮게 나오게 할 수 있다. 편의를 위해 이 로스함수를 NT-Xent (the normalized temperature-scaled cross entropy loss) 라고 부른다.
-
로스함수를 계산하고, 이를 이용해 를 학습한다.

위에서 설명한 내용을 알기 쉽게 의사코드로 설명한 내용이다.
학습
- 배치사이즈가 8192이라면 16382개의 negative examples이 나오므로 큰 배치사이즈가 성능에 영향을 끼친다. 논문에서는 256~8192의 N을 사용한다. (한 모델만 학습한것이 아님)
- 큰 배치사이즈와 동시에 standard SGD/Momentum을 사용하는건 불안정 할 수 있다. 그러므로 LARS optimizer를 사용한다.
- resnet은 BN을 쓰지만, 로컬에서 쓰는 BN은, 긍정쌍이 같은 기기에서 계산되어 모델이 정보 누수를 악용할 수 있다. 이를 막기 위해 Global BN을 사용한다
Data Augmentation for Contrastive Representation Learning

위 이미지는 각 데이터 증강이 어떻게 이미지를 변환시키는지 보여준다.
Composition of data augmentation operations is crucial for learning good representations
어떤 데이터 증강이 어떤 효과를 보이는지 보기 위해 두개의 증강 방법을 순서대로 진행하거나, 한개만 증강하여 heatmap으로 나타내 보자
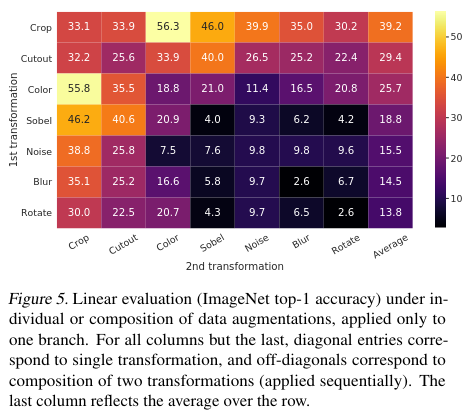
특히 두각을 보이는 조합이 보이는데, Crop + Color 이다. Crop만 했을때의 pixel intensities 히스토그램을 보며 왜 Crop + Color가 강한지 확인해보자.
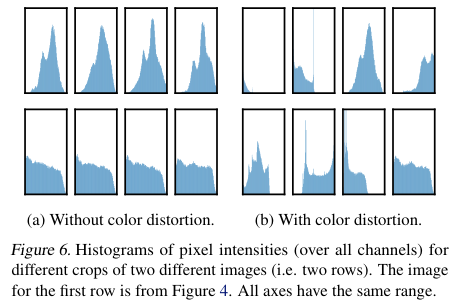
Crop만 하고 Color distortion을 안하면 모델은 진정한 이미지의 표현보다는 색상의 분포를 학습하게 된다. 그러므로, cropping과 color distortion을 합치는것은 일반화 가능한 특징에 대해 배우는것에 핵심적이다.
Contrastive learning은 supervised learning보다 더 강력한 증강이 필요하다.
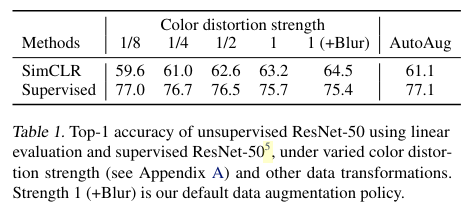
오른쪽으로 갈수록 증강이 강해지는데, SimCLR은 성능이 향상되는 반면, Supervised learning에서는 차이가 없거나 오히려 성능이 안 좋아지는걸 볼 수 있다.
Architectures for Encoder and Head
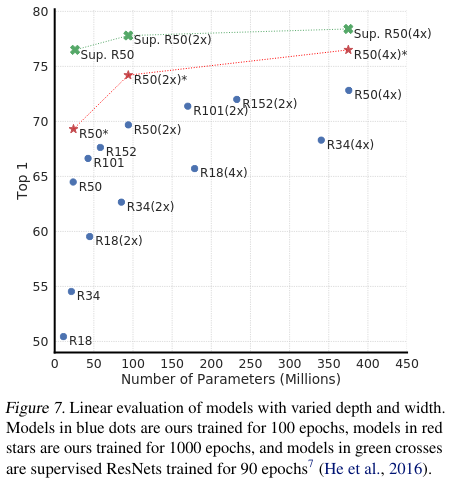
(놀랍지 않겠지만) 큰 모델이 더 성능이 좋다.
A nonlinear projection head improves the representation quality of the layer before it
우리의 이미지 표현은 를 거친 다음 로스함수에 들어가는데, 표현을 사용하는데는 에 들어가기 이전의 를 쓰는게 를 쓰는것 보다 낫다. 왜 그럴까? g는 두개의 다른 변환을 거친 이미지를 같은 이미지로 판별하기 위해 이미지의 색상같은 원래 이미지 표현에 있던 정보를 잃는다. 논문에서는 이를 검증하기 위해 와 중 하나를 사용하여 “학습시 이미지에 무슨 변환을 거쳤는지 알아내는” 문제를 풀게 학습 해보았다.
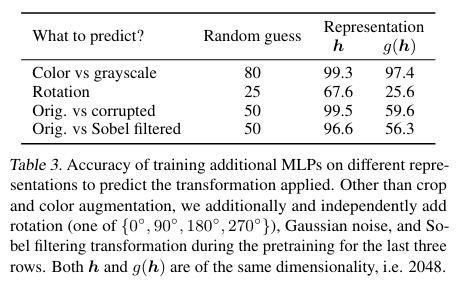
에 정보가 더 많이 남아있어, 가 보다 높은 정답률을 보이는걸 알 수 있다.

와 의 t-SNE 시각화이다.
Loss Functions and Batch Size
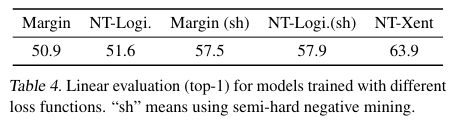
NT-Xent는 온도에 의해서 어려운 문제에 더 가중치를 두게되어 logistic loss나 margin loss보다 성능이 좋다. 다른 loss 함수는 직접 semi-hard negative mining을 적용해야한다. NT-Xent를 다른 자주 쓰이는 contrastive loss functions과 비교하고, 그 결과를 통해 NT-Xent가 다른 함수보다 우수함을 보이자. (sh)는 semi-hard negative mining.
배치 사이즈와 에포크를 다르게 하여 성능을 비교해보자.
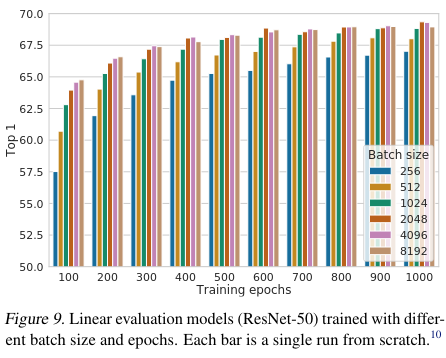
supervised learning과 다르게, contrastive learning은 큰 배치 사이즈로 오래 학습 할 수록 많은 negative examples을 제공하게 되어 성능에 큰 영향을 끼친다.
Evaluation
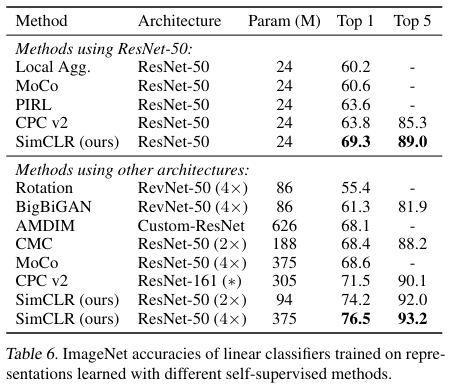
다른 self-supervised methods 와의 비교.
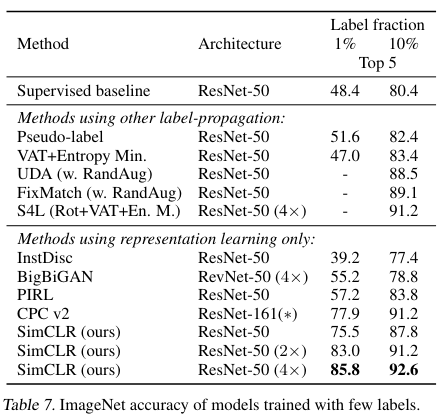
1%의 데이터와 10%의 데이터를 추가한 Semi-supervised learning .
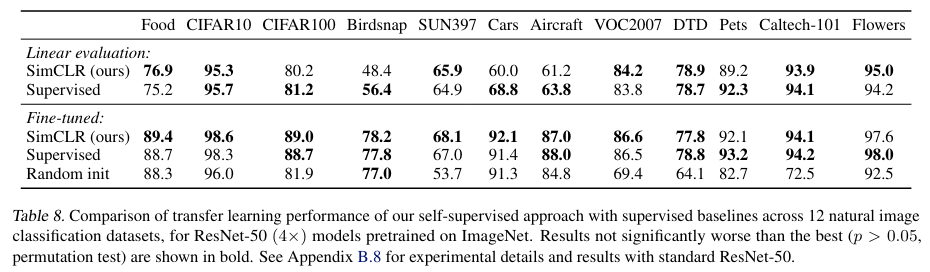
전이 학습 성능.
Conclusion
이 논문에서는 간단하지만 효과적인 프레임워크를 제안했고 그 구성요소에 대해 살펴보면서 하나하나가 어떤 효과를 가지고있는지 확인했다.
이 간단한 프레임워크는 최근 자기지도학습에 대한 관심이 높아졌음에도 아직 잠재력이 저평가 되어있다는것을 보여준다!
“The strength of this simple framework suggests that, despite a recent surge in interest, self-supervised learning remains undervalued.”