- 제목: You Only Look Once: Unified, Real-Time Object Detection
- 저자: Joseph Redmon, Santosh Divvala, Ross Girshick, Ali Farhadi
- 게재된 학회: CVPR 2016 (Conference on Computer Vision and Pattern Recognition)
- 발표 연도: 2016
- 논문 링크: https://arxiv.org/pdf/1506.02640
참고한 글들:
Summary
YOLO는 컴퓨터 비전의 과제중 하나인 객체 탐지를 수행하는 모델이다.
YOLO 이전의 객체 탐지: 이전 모델들은 슬라이딩 윈도우 방식으로 이미지 전체를 돌아다니면서 분류하거나(DPM), 분류 CNN모델을 활용하여 객체가 있을만한 후보영역을 몇천개 생성한후, 그 후보 영역 각각에 CNN을 수행하는 방식으로(R-CNN)으로 만들어져 있었다.
이전 모델의 방식들은 복잡한 파이프라인으로 이루어져서 속도 저하가 일어났고, 각각의 영역에 CNN을 적용하기 때문에 전체 이미지에 대한 컨텍스트도 부족했다.
YOLO의 핵심 방법론: YOLO는 객체 탐지를 하나의 회귀문제로 바라보았다. 후보영역 추출과 분류 없이, 이미지를 한번만 보고 객체의 위치와 종류를 예측하도록 설계했다.
YOLO는 하나의 회귀 문제로 바라본 모델 덕에 복잡한 파이프라인이 없을 수 있었고, 그로인해 속도가 훨씬 빠르게 되었다. 또한, 항상 이미지 전체를 보기 때문에 전체 이미지의 컨텍스트가 들어가 배경을 객체로 잘못 탐지하는 배경 오류도 줄어들 수 있게 되었다.
Unified Detection
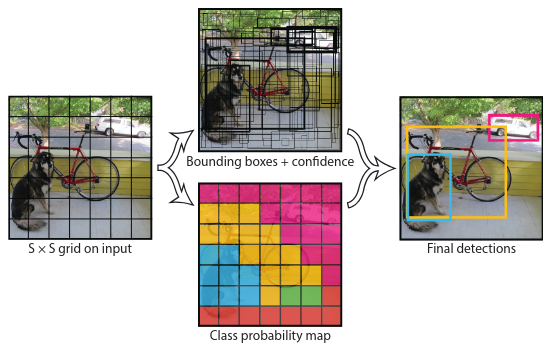
어떻게 YOLO는 하나의 뉴럴네트워크로 객체탐지를 해낼 수 있었을까?
YOLO는 일단 이미지를 그리드로 나눈다. 만일 어떤 객체의 중점이 특정 cell 안에 들어가 있다면, 그 cell은 객체를 탐지할 책임이 있다.
각각 셀은 개의 bounding boxes와, 박스에 대한 confidence scores를 예측해야한다. 박스는 를 예측하는데, 는 각 셀의 몇%에 객체의 중심이 있는지이고, 는 전체 이미지 대비 몇%의 너비와 높이를 가지고 있는지이다. confidence 의 정의는 다음과 같다. (IoU)
또한 각 cell은 다음과 같은 conditional class probabilities 를 개 예측해야한다.
이러한 예측은 결국 텐서로 인코딩 될 수 있다.
test time에는 conditional class probabilities 와 confidence predictions를 곱하여 각 클래스별의 confidence scores를 얻는다.
논문에서는 PascalVOC 에서 YOLO를 쓰기 위해 로 나누고, 각 셀당 개의 박스를 예측하며, 개의 클래스로 분류한다.
Architecture
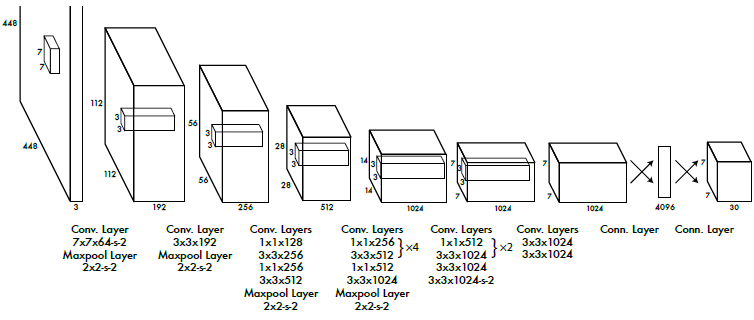
사전학습 → 본모델
YOLO는 위와 같은 아키텍쳐로 이루어져 있는데, 처음의 20개의 Conv layer와 Avg pool, FC를 연결해 ImageNet에 대해 사전학습시켜 88%의 top-5 정확도를 달성했다. 그 다음, detection 작업을 수행할 수 있도록 4개의 Conv layer와 2개의 FC를 추가한 후 입력크기를 에서 로 늘렸다. 최종 레이어를 제외한 모든 레이어의 활성화 함수는 Leaky ReLU를 사용했다. ()
오류함수 최적화 1: 객체 - 배경 불균형
대부분의 이미지에는 객체가 있는 셀보다 객체가 없는 셀이 더 많아서 단순 SSE로는 객체가 없는 셀이 객체가 있는셀을 압도해서 학습이 불안정해질 수 있음. 이를 막기 위해서 두개의 파라미터를 도입함.
객체가 있는 셀에는 가중치를 5, 객체가 없는 셀에는 가중치를 0.5를 적용하여 해결함
오류함수 최적화 2: 큰 상자 - 작은상자
큰 박스를 예측할때는 벗어난 부분이 조금 커도 별로 큰 문제가 되지 않지만, 작은 상자를 예측할 때는 벗어난 부분이 큰 문제가 된다. 하지만 SSE에서 이 둘의 오류를 똑같게 처리하기 때문에, 우리는 나 를 직접 예측하지 않고 나 를 예측하여 이 문제를 해결한다.
오류함수 최적화 3: 책임 할당
셀에서 예측한 B개의 예상 박스중 실제 정답과의 IoU가 가장 높은것에만 책임을 부여한다. 이를 통해 각 예측기가특정 크기나 비율의 객체를 예측하는데 전문성이 생기도록 유도한다.
최종 오류함수:
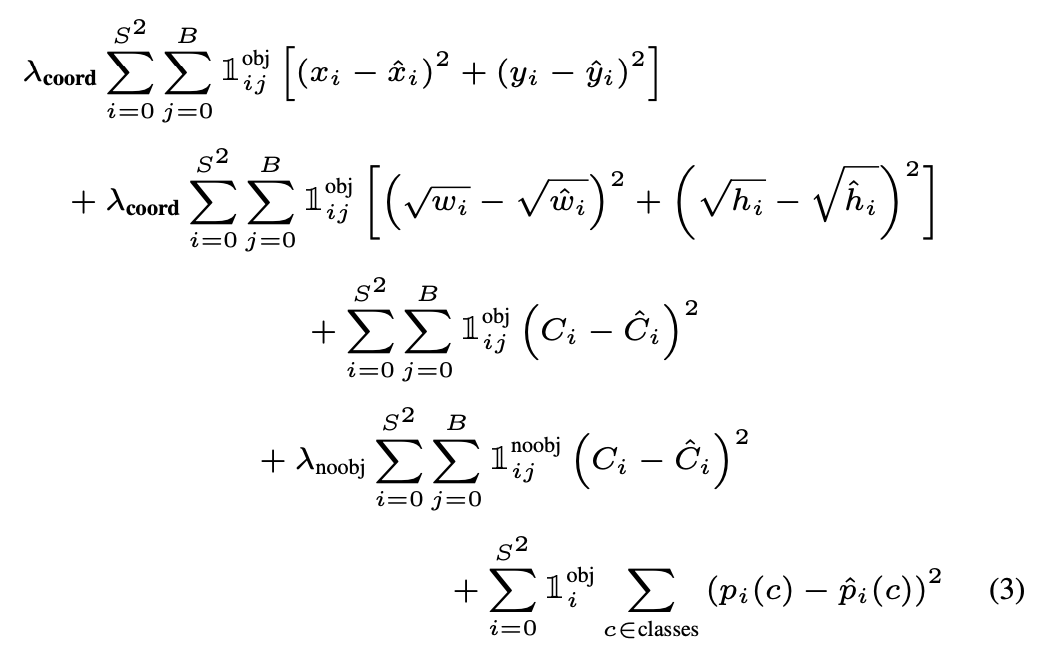 는 i번째 셀에 obj가 있는지 판단하는 인디케이터 펑션,
는 i번째 셀에 obj가 있는지 판단하는 인디케이터 펑션,
한계
- 한 셀 안에 B개밖에 예측 할 수 없음.
- 학습했던 비율이 아닌 새로운 비율의 객체를 일반적으로 인식하는데 어려움을 겪음
- loss function이 작은 상자 오류와 큰 상자의 오류를 동일하게 처리함
Comparison to Other Detection Systems
기존 방법들은 탐지문제를 여러가지 문제로 나누어 복잡한 파이프라인을 통과해서 해결했던 반면, YOLO는 하나의 네트워크만을 한번 통과해 탐지문제를 빠르게 해결함. 이를 통해 YOLO는 다른 탐지 모델들은 하지 못했던 실시간성을 보여줌.
Experiments
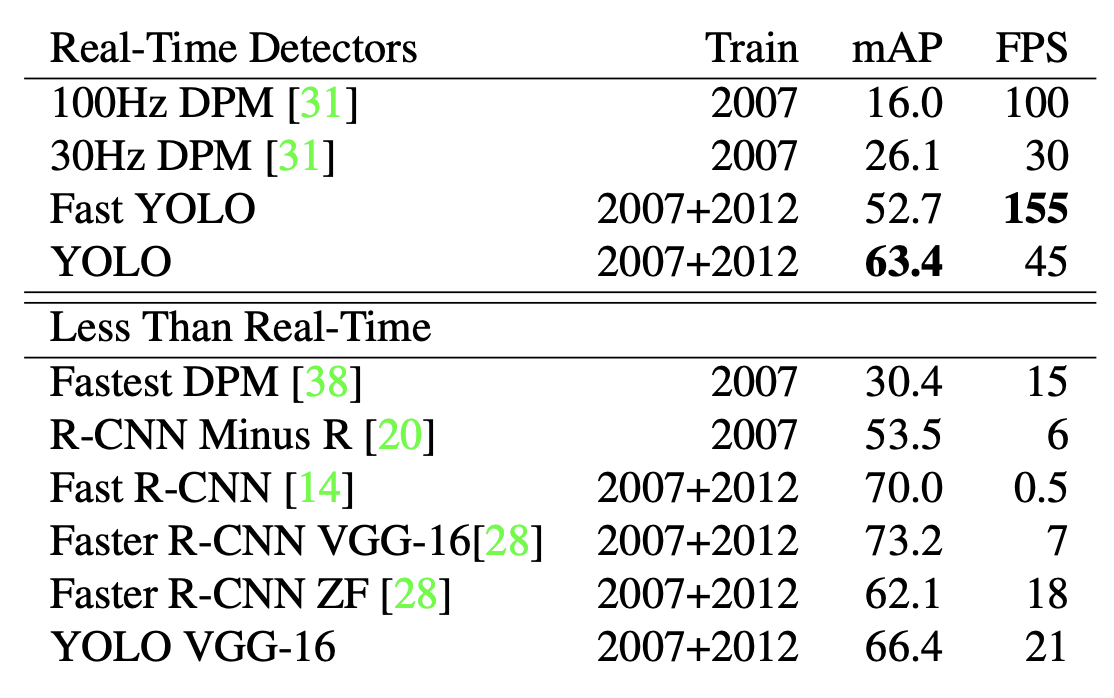 Table 1: Real-Time Systems on PASCAL VOC 2007.
Table 1: Real-Time Systems on PASCAL VOC 2007.
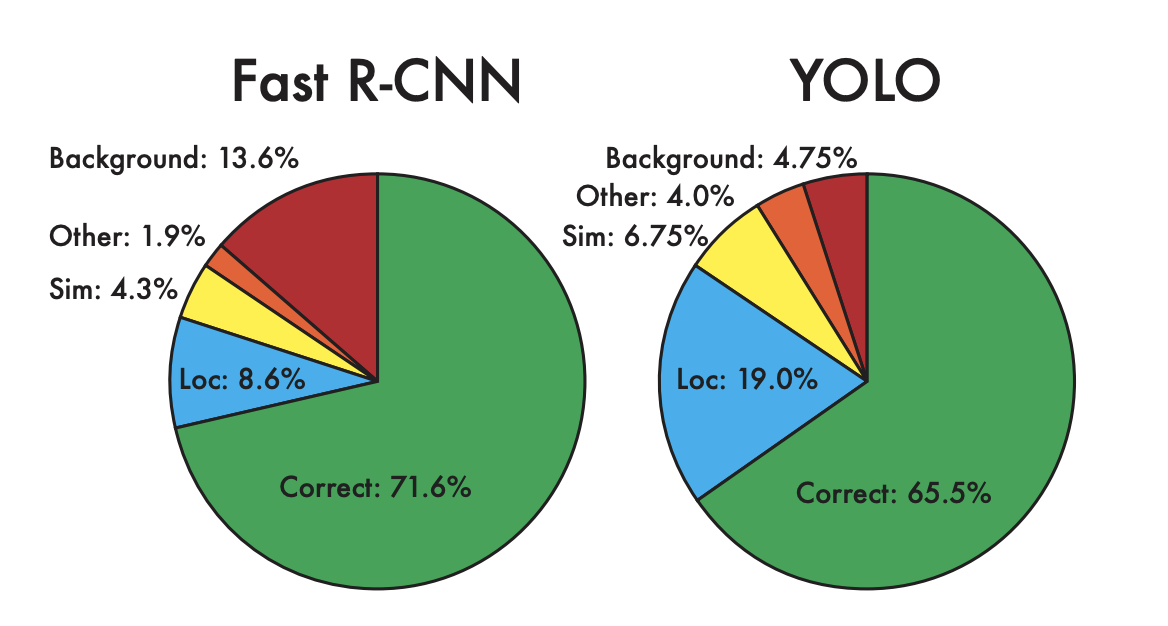 Figure 4: Error Analysis: Fast R-CNN vs. YOLO
Figure 4: Error Analysis: Fast R-CNN vs. YOLO
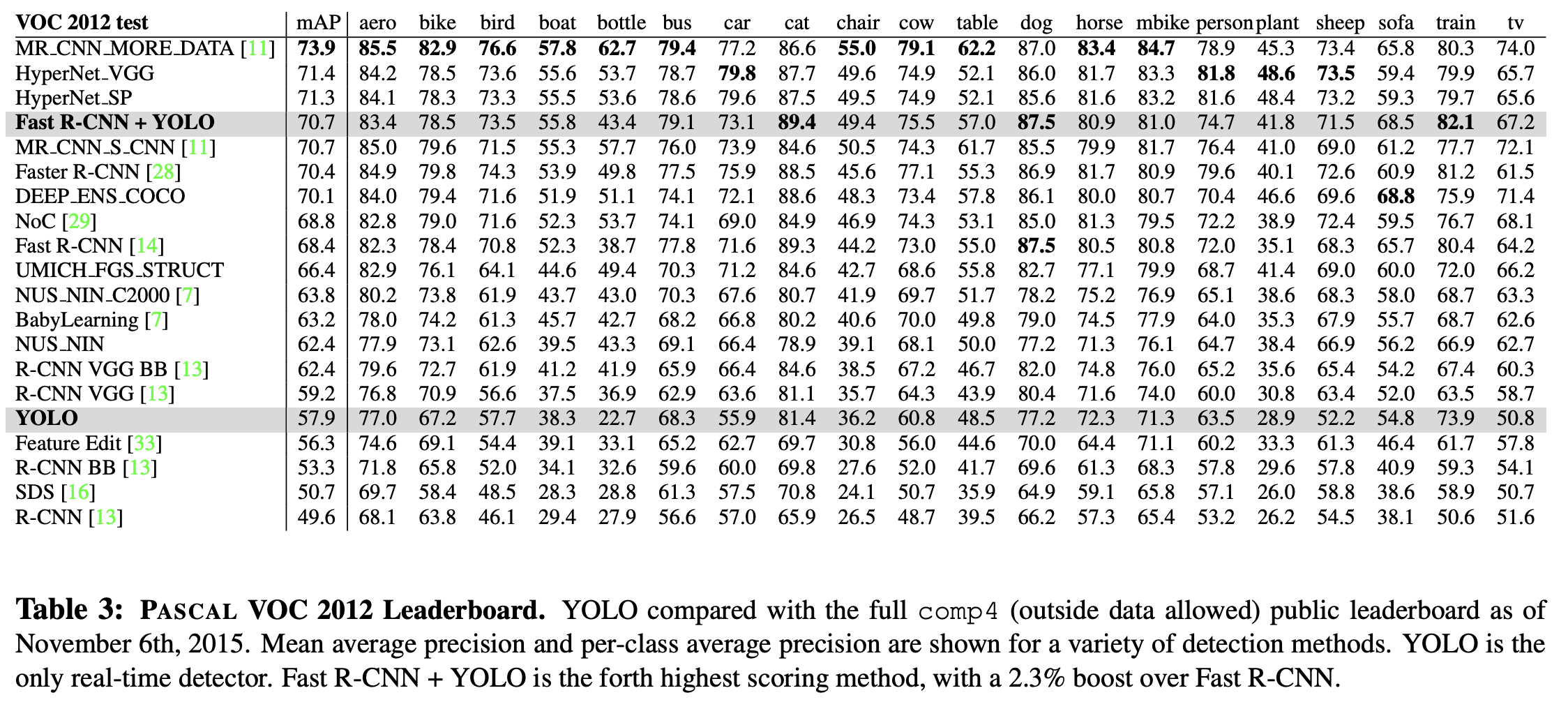 YOLO는 Fast R-CNN이 약한 부분인 백그라운드를 더 잘푼다는 점에 입각해 YOLO와 비슷한 영역을 예측하고 있다면 확률에 부스트를 주게 해본 결과, 두 모델이 상호보완적으로 작동하여 높은 성능을 내는것을 보여준다.
YOLO는 Fast R-CNN이 약한 부분인 백그라운드를 더 잘푼다는 점에 입각해 YOLO와 비슷한 영역을 예측하고 있다면 확률에 부스트를 주게 해본 결과, 두 모델이 상호보완적으로 작동하여 높은 성능을 내는것을 보여준다.
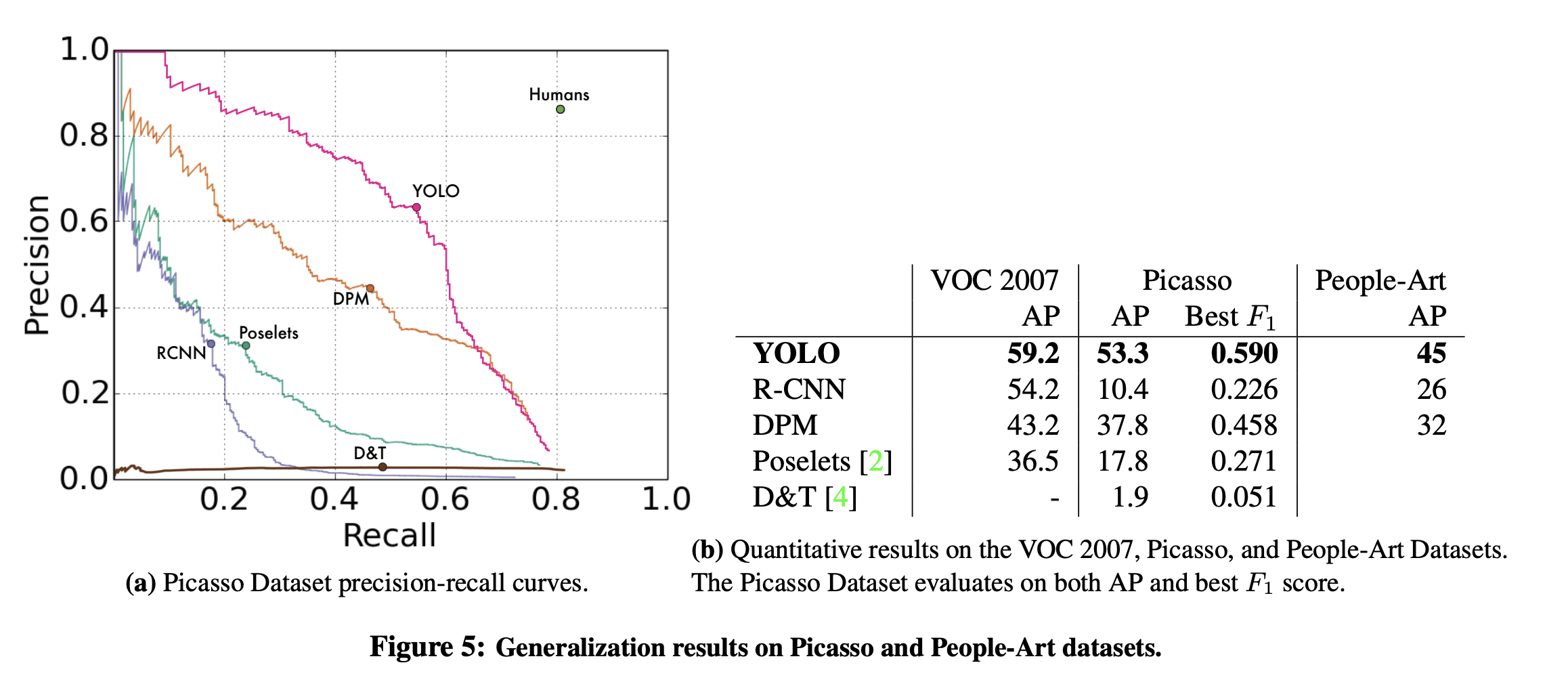 YOLO는 일반적인 이미지로 학습을 시킨 다음 예술 데이터셋에 대해 테스트를 시켰을때 다른 모델보다 뛰어난 일반화 성능을 보여준다
YOLO는 일반적인 이미지로 학습을 시킨 다음 예술 데이터셋에 대해 테스트를 시켰을때 다른 모델보다 뛰어난 일반화 성능을 보여준다